|
Il
flusso delle news (definite ad oggi come la serie di articoli
scaricati dai vari newsgroups) ha subito negli anni un'importante
evoluzione, nascendo col noto fenomeno delle mailing-list
le quali prevedono l'invio di una singola copia dell'articolo
richiesto a tutti gli indirizzi di posta elettronica di coloro
che ne hanno fatto richiesta.
Il sistema in sé risulta parecchio inefficiente e ben
poco robusto dal momento che gruppi che contano un discreto
numero di subscribers riescono difficilmente a gestire un
flusso ininterrotto di messaggi senza andare incontro a disagi.
Disagi che sono facilmente riconducibili ad una richiesta
eccessiva di spazio libero nell'hard disk dei destinatari
e dell'organizzatore della mailing-list, ad un utilizzo spropositato
delle risorse dei processori, ad un'estrema difficoltà
nelle operazioni di manutenzione ed organizzazione delle liste
di articoli e di indirizzi, all'impossibilità di poter
scaricare e leggere solamente gli articoli di proprio interesse
e così via.
Risulta quindi piuttosto chiaro che la necessità di
centralizzare il sistema era davvero indispensabile.
Questa tendenza ha dato così il via alla decadenza
delle mailing-list, rimaste comunque in vita in piccoli gruppi
ed alla diffusione dei newsgroups ed al sistema definito USENET.
USENET rivoluziona il modello di accesso alle news in quanto
si compone di un diversi database delle news posti su server
centrali che rappresentano l'unica interfaccia tra utente
e database delle news ed al quale possono accedere liberamente
o tramite autenticazione gli utenti ad esso connessi tramite
applicazioni appositamente create. Il diffuso Microsoft Outlook
Express ed il suo corrispondente nonché concorrente
Netscape Communicator sono solo alcuni dei tanti disponibili.
Ciascun database delle news dialoga col corrispondente database
posto sui server collegati dalla rete, formando così
un flusso di informazioni che non si ferma mai in un punto.
Parlando di proporzioni, si stima che il più grande
server delle news riceva ed ospiti 800.000 articoli al giorno,
con una media di nove articoli al secondo.
Partendo da questo presupposto pertanto si comprende come
i requisiti di spazio siano altamente importanti.
A
differenza delle mailing list queste necessità non
derivano da una mancata ottimizzazione del sistema ma sono
piuttosto il risultato di una popolarità che cresce
a proporzioni esponenziali: si parla infatti di un raddoppio
dell'intensità di traffico ogni 10-18 mesi, con una
presenza di circa 25.000 newsgroup.
Tuttavia la lista dei gruppi in rete non è affatto
omogenea: è infatti possibile operare una netta distinzione
in base alla popolarità ossia alla frequentazione media
giornaliera di ciascun gruppo.
Si può in tal modo ricavare il nucleo dei newsgroup
che dominano sugli altri: i cosiddetti mainstream che contati
ammontano a circa 730.
Gli archivi delle news racchiudono al loro interno una serie
di informazioni utili quali ad esempio la lista dei newsgroup
disponibili, l'indice che identifica ciascun messaggio all'interno
di un particolare newsgroup, il corpo, l'oggetto, l'autore
e la data di invio dell'articolo.
La procedura che il comune utente seguirà sarà
pertanto non il download di tutti i messaggi nella loro completezza
ma rispettivamente:
1. il download della lista dei newsgroup
2. la scelta del newsgroup di proprio interesse
3. il download della lista di messaggi di cui si compone il
newsgroup
4. la scelta del messaggio di proprio interesse
5. il download del corpo del messaggio
permettendo così di frammentare i passaggi e di ridurre
drasticamente il carico di lavoro sia dal lato client che
naturalmente dal lato del server delle news.
Il flusso di dati della comunicazione NNTP ustilizza un tipo
di connessione molto simile al TCP ed è permesso grazie
ad una struttura di domande/risposte accumunabili al modello
SMTP: un comando inviato dall'utente genera una determinata
reazione del server il quale compierà un l'operazione
richiesta in base alla disponibilità di dati contenuti
nei database delle news. E finalmente, una volta terminato
il lavoro, restituirà al mittente una risposta.
| Analisi
dell'attività di USENET |
Per
ottenere una visione completa ed approfondita del fenomeno
USENET è necessario avere sottomano un paio di analisi,
due punti di vista differenti che affiancati danno un'idea
del panorama del sistema.
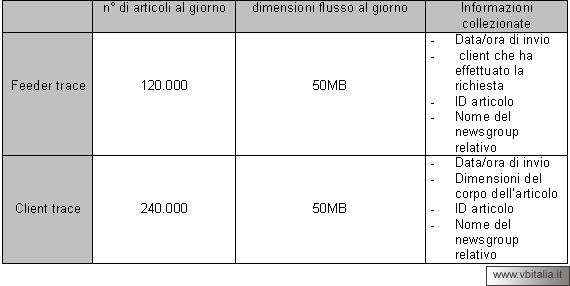
Il primo livello di studio rappresenta la portata del flusso
di articoli che vengono archiviati giornalmente sui server
delle news ed è denominato Feeder trace, una definizione
sicuramente riuscita che vede l'utente come colui che rifornisce
il server delle news prescelto. Il secondo livello è
invece il Client trace che monitorizza il numero di articoli
richiesti e letti dai client.
L'analisi viene condotta generalmente con sistemi il meno
intrusivi possibile. Questo significa che qualsiasi sistema
di collezionamento dati deve avere le seguenti caratteristiche:
· deve poter ricevere dati senza alterarne il flusso
· non deve sovraccaricare il già pesante lavoro
del server delle news
Le informazioni collezionate per ciascuno dei due casi sono
facilmente riassumibili nella tabella sottostante (fonte:
COMPAQ Research):
Il
monitoraggio delle informazioni nel caso del Feeder trace
viene effettuato collegando una macchina alla stessa subnet
del server, permettendole di avviare un'applicazione (TCPDump)
di controllo sui pacchetti di dati che affluiscono al server
principale. Una volta ricevute le informazioni, queste vengono
registrate e ne viene tenuta traccia tramite un file di log.
L'analisi dei dati in uscita inviati dal server ai client
avviene collegando il server ad una seconda macchina su cui
gira una versione modificata del pacchetto di applicazioni
InterNetNews (INN) il quale permette ai server di compiere
determinate operazioni e di comprendere i comandi e le richieste
provenienti dall'esterno. Per un maggior approfondimento sul
tema verrŕ dedicato un capitolo a questo strumento, all'interno di un successivo articolo.
La scelta utilizzare INN rispetto a TCDump in fase di Client
trace è dovuta alla difficoltà di recuperare
le dimensioni dell'articolo in uscita: il protocollo NNTP
non prevede infatti la dichiarazione esplicita delle dimensioni
degli articoli quando questi passano da un news server all'altro.
Sarebbe quindi necessario analizzare byte per byte la risposta
ottenuta dal server per poi stabilire l'inizio e la fine dell'articolo
e, effettuando una semplice differenza, recuperarne le dimensioni
totali.
|